République
Française
Texte provenant des pdfs trouvés sur data.gouv.fr
Texte extrait des pdfs trouvés sur data.gouv.fr
Description
Ce dataset contient le texte extrait de 6602 fichiers qui ont l'extension pdf dans le catalogue de ressources de data.gouv.fr.
Le dataset contient que les pdfs de 20 Mb ou moins et qui sont toujours disponibles sur l'adresse URL indiquée.
L'extraction a été réalisée avec PDFBox via son wrapper Python python-pdfbox. Les PDFs qui sont des images (scans, cartes, etc)
sont détectés avec une heuristique simple : si après la conversion au format texte avec pdfbox, la taille du fichier produit est inférieure à 20 bytes on considère qu'il s'agit d'une image.
Dans ce cas, on procède à la OCRisation. Celle-ci est réalisé avec Tesseract via son wrapper Python pyocr.
Le résultat sont des fichiers txt provenant des pdfs triés par organisation (l'organisation qui a publiée la ressource). Il y a 175 organisations dans ce dataset, donc 175 dossiers.
Le nom de chaque fichier correspond au string {id-du-dataset}--{id-de-la-ressource}.txt.
Input
Catalogue de ressources data.gouv.fr.
Output
Fichiers texte de chaque ressource type pdf trouvée dans le catalogue qui a été converti avec succès et qui a satisfait les contraintes ci-dessus.
L'arborescence est la suivante :
.
├── ACTION_Nogent-sur-Marne
│ ├── 53ba55c4a3a729219b7beae2--0cf9f9cd-e398-4512-80de-5fd0e2d1cb0a.txt
│ ├── 53ba55c4a3a729219b7beae2--1ffcb2cb-2355-4426-b74a-946dadeba7f1.txt
│ ├── 53ba55c4a3a729219b7beae2--297a0466-daaa-47f4-972a-0d5bea2ab180.txt
│ ├── 53ba55c4a3a729219b7beae2--3ac0a881-181f-499e-8b3f-c2b0ddd528f7.txt
│ ├── 53ba55c4a3a729219b7beae2--3ca6bd8f-05a6-469a-a36b-afda5a7444a4.txt
|── ...
├── Aeroport_La_Rochelle-Ile_de_Re
├── Agence_de_services_et_de_paiement_ASP
├── Agence_du_Numerique
├── ...
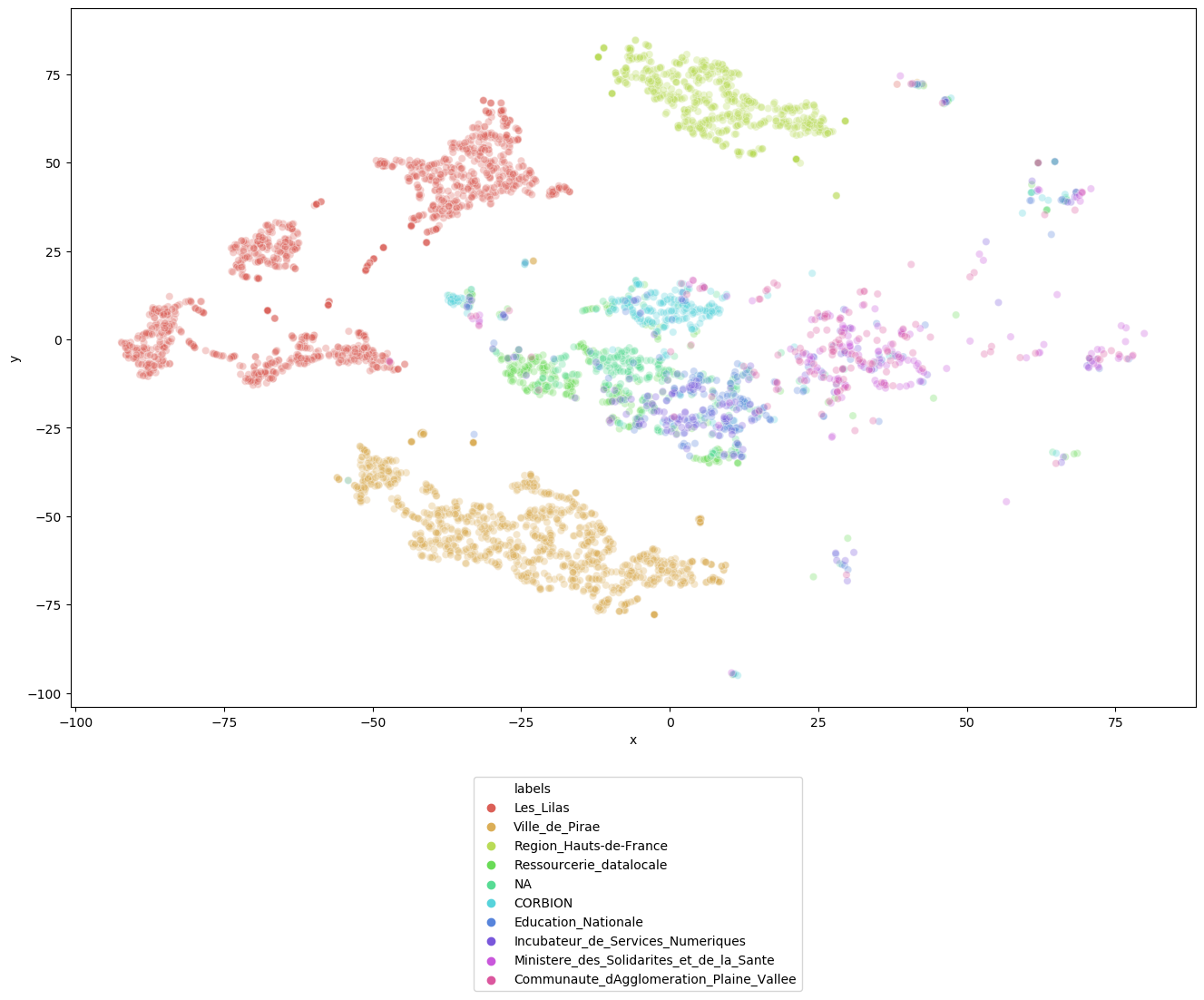
Distribution des textes [au 20 mai 2020]
Le top 10 d'organisations avec le nombre le plus grand des documents est:
[('Les_Lilas', 1294),
('Ville_de_Pirae', 1099),
('Region_Hauts-de-France', 592),
('Ressourcerie_datalocale', 297),
('NA', 268),
('CORBION', 244),
('Education_Nationale', 189),
('Incubateur_de_Services_Numeriques', 157),
('Ministere_des_Solidarites_et_de_la_Sante', 148),
('Communaute_dAgglomeration_Plaine_Vallee', 142)]
Et leur aperçu en 2D est (HashFeatures+TruncatedSVD+t-SNE) :
Code
Les scripts Python utilisés pour faire cette extraction sont ici.
Remarques
Dû à la qualité des pdfs d'origine (scans de basse résolution, pdfs non alignés, ...) et à la performance des méthodes de transformation pdf-->txt, les résultats peuvent être très bruités.
- Producteur
Pavel Soriano
Ce jeu de données a été publié à l'initiative et sous la responsabilité de Pavel Soriano.- Dernière mise à jour
- 20 mai 2020
Fréquence de mise à jour non respectée
Couverture temporelle non renseignée
Couverture spatiale non renseignée
Vues
0
Téléchargements
0