République
Française
Comment mettre en forme des données tabulaires ? L'exemple des données du projet de loi de finances
Le hackathon datafin a permis de montrer que les données du projet de loi de finances ne sont pas faciles à réutiliser.

La principale difficulté provient du fait que les données sont réparties en 19 fichiers Excel différents !
La nomenclature des fichiers n'est pas évidente. On se perd un peu entre les missions, les titres, les actions, les sous-actions, le budget général, les comptes spéciaux, etc.
Un atelier sur la mise en forme des données a permis d'établir un certain nombre de bonnes pratiques et de proposer une mise en forme plus pertinente des données.
Quelques règles simples
- Ne pas confondre les métadonnées et les données

Le fichier du budget général sur l'axe nature comme les autres fichiers contient à la fois des métadonnées. Il est recommandé de mettre les métadonnées dans la documentation ou dans un fichier à part plutôt que dans les données.
- Avoir des noms de colonnes explicites

Les données de la performance budgétaire contiennent des colonnes qui ne sont pas forcément compréhensibles pour un réutilisateur externe à l'administration. Pas facile de savoir ce qu'on entend par "Code PGM". Il est préférable d'appeler tout simplement la colonne "code_programme".
- Ne pas mélanger des niveaux d'observations différents
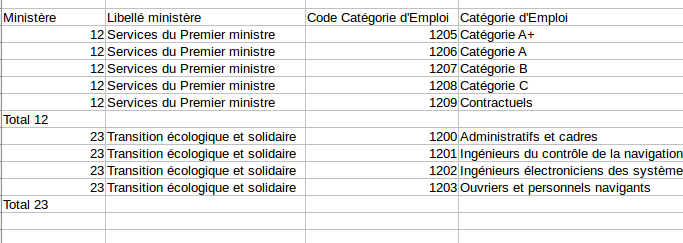
Le fichier des emplois par ministère met dans la même table la ventilation des emplois par ministère et catégorie d'emploi et les sous-totaux par ministère. Cela crée de la confusion. Il suffit d'avoir le détail de la ventilation des emplois par ministère et catégorie d'emploi et on peut facilement recomposer la ventilation par ministère.
- Utiliser le format CSV et l'encodage UTF-8.
Les données du projet de loi de finances sont bien diffusées en CSV. Elles pourraient être améliorées en utilisant l'encodage UTF-8, beaucoup plus standard que l'encodage latin-1.
- Bien enregistrer les nombres comme des nombres plutôt que comme des chaînes de caractères
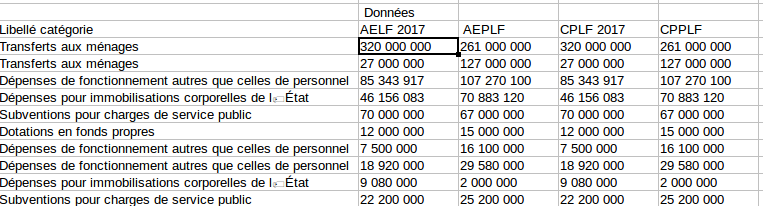
Dans ce fichier, on voit bien que les nombres sont interprétés comme des chaînes de caractères. Impossible de faire des opérations mathématiques dessus sans effectuer au préalable un petit travail de conversion.
Réorganiser les données pour simplifier leur usage
Au delà de ces simples règles de mise en forme, on peut réfléchir à la bonne manière d'organiser les données pour simplifier leur usage.
Bien comprendre les données du projet de loi de finances
En fait, tous ces tableaux contiennent essentiellement deux variables, les autorisations d'engagement (AE) et les crédits de paiement (CP) ventilées selon trois axes :
- le type de budget : budget général, budget annexe, comptes spéciaux et comptes de concours financiers
- la destination : la finalité de la dépense.
- la nature : la nature de la dépense (masse salariale, etc)
La subtilité vient du fait que la destination peut être définie à plusieurs niveaux :
- la mission
- le programme
- l'action
- la sous action
De même, la nature peut être définie à deux niveaux :
- le titre
- la catégorie
Les différents fichiers ne sont que des combinaisons différentes de ces trois axes.
Et si on mettait tout dans un même fichier ?
Si on veux faire un tableau lisible et interprétable par un humain pour un usage précis, il est intéressant de faire un choix et de proposer une vue des données qui donne par exemple pour un type de budget, la ventilation par programme et titre. En revanche, si on veut diffuser la donnée la plus fine possible pour permettre la plus grande liberté de réutilisation, on peut tout mettre dans un seul tableau au niveau le plus fin possible.
Dans l'idéal, on aimerait donc faire un grand tableau les autorisations d'engagement et les crédits de paiement ventilés par type de budget, sous action (niveau le plus fin de l'axe destination) et catégorie (niveau le plus fin de l'axe nature).
Malheureusement, les données diffusées ne nous permettent pas de reconstituer ce niveau de granularité.
A titre d'exemple, nous diffusions donc un fichier avec les autorisations d'engagement et les crédits de paiement ventilés par type de budget, action et catégorie.
Ce fichier permet de recalculer assez facilement la majorité des autres fichiers diffusés actuellement.
Et si on faisait un schéma ?
Pour aller plus loin, on peut même faire un schémahttps://frictionlessdata.io/specs/table-schema/) qui précise pour chaque colonne :
- le nom de la colonne
- le type : chaîne de caractère, date, nombre entier, etc
- le caractère obligatoire de la colonne
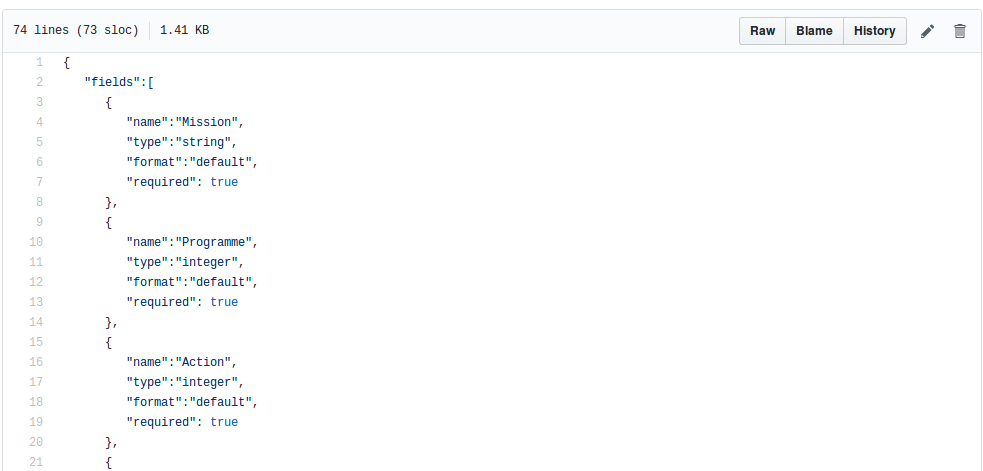
On pourrait proposer le schéma suivant pour le PLF : schema.json
Pour aller plus loin
- Le format tidy-data par Hadley Wickham
- La notion de schéma sur le site frictionlessdata
- Un guide pour bien organiser ses données dans un tableur par Karl Broman